Nói đến công nghệ AJAX , người ta thường nghĩ ngay đến đối tượng XMLHttpRequest, nhưng thực ra AJAX không chỉ có vậy. Và chúng ta cũng không chỉ có AJAX. Bài viết này xin giới thiệu một số kỹ thuật tải dữ liệu mà các nhà phát triển web đang khai thác trong nỗ lực kéo các ứng dụng web lại gần hơn với các ứng dụng desktop.
Trong các ví dụ minh họa kèm theo, PHP được dùng làm server script. Do kiến thức có hạn, rất mong nhận được sự góp ý của các bạn về những điểm chưa chính xác.
Nào, chúng ta bắt đầu.
I. Dùng Iframe làm bộ đệm.
Ngay từ phiên bản 4.0, Microsoft đã đưa vào IE một đối tượng gọi là Iframe cho phép nhúng 1 trang web vào trong 1 trang khác. Phiên bản Netscape 4 cũng bắt đầu sử dụng đối tượng Layer để quản lý trang web theo nhiều tầng. Cả Iframe và Layer đều có 1 thuộc tính src liên kết với 1 địa chỉ web bên ngoài, và thông qua Java Script, có thể lấy dữ liệu từ đây để chèn cập nhật nội dung trang chính.
Sau đó, vì IE không hỗ trợ Layer, trong khi Netscape lại hỗ trợ Iframe nên Iframe trở nên phổ biến hơn. Dưới đây, chúng ta sẽ thử làm 1 ví dụ về cách tải trang thông qua 1 iframe để cập nhật nội dung cho trang web chính mà không cần tải lại nó.
Nhưng trước hết bạn hãy hình dung 1 Iframe, nó là 1 inline frame, nằm trong trang web chính, có 1 kích thước cụ thể được quy định bằng CSS. Nếu kích thước của nó là 0x0, người sử dụng sẽ không thấy được nó, dù rằng nó vẫn hiện diện như 1 thành phần của trang web.
Mặt khác, theo cấu trúc DOM và cách xử lý của nhân Java Script trong trình duyệt, thì quan hệ giữa trang chính và iframe là parent - child. Do đó, 1 script trên trang chính có thể truyền các tham số vào 1 script trong Iframe, và ngược lại, miễn là chúng tuân thủ nguyên tắc an toàn dữ liệu theo cơ chế cùng nguồn gốc, nghĩa là trang nằm trong iframe và trang chứa nó phải xuất phát từ cùng một domain.
Như vậy, nếu iframe load 1 trang mới, dưới dạng 1 đoạn HTML, chúng ta có thể gán đoạn HTML này vào 1 phần tử nằm trên parent, để thay đổi nội dung cho parent, thông qua phương thức innerHTML.
Vấn đề đặt ra là nếu chuỗi trả về nằm trên nhiều dòng, script có thể gây ra lỗi. Cho nên tôi đề nghị giải pháp đặt tất cả chuỗi trả về vào trong 1 textArea, sau khi iframe load hoàn chỉnh, chúng ta gọi 1 hàm JavaScript để lấy dữ liệu từ textArea này vào 1 biến, sau đó gửi ngược lên parent.
Tiến trình cụ thể gồm các bước sau :
- Người sử dụng nhấn vào 1 liên kết có đích là iframe.
- Iframe tải nội dung trang chứa trong liên kết
- Iframe tải hoàn chỉnh, 1 script trong iframe chuyển dữ liệu lên parent.
- Parent cập nhật nội dung vào các phần tử trình bày.
- Người sử dụng tiếp cận với thông tin vừa cập nhật.
Để làm điều này, đầu tiên chúng ta tạo 1 trang web đơn giản với 2 hàm JavaScript nhỏ trên header:
<script type="text/javascript">
function rel(ob){return document.getElementById(ob);}
function gTxt(ob,txt){rel(ob).innerHTML=txt;}
</script>
Hàm rel lấy vào tham số là định danh của 1 phần tử trên trang, và trả về phân tử đó. Hàm gTxt có tác dụng gán 1 chuỗi vào 1 phần tử.
Và phần trình bày là 1 bảng gồm 2 phần. Bên trái chứa các liên kết đến từng chủ đề, khi nhấn vào đây, nội dung chủ đề sẽ được tải vào trang bên phải. Lưu ý là không phải chúng ta đặt 2 iframe 2 bên. Như vậy quá thô thiển và chẳng có gì thú vị ! Đây sẽ chỉ là 2 nửa của 1 bảng:
<table width="550" height="350" border="0" cellspacing="0" cellpadding="10">
<tr>
<td valign="top" width="150" style="background-color:#fffff4;color:blue;">
<h3>News</h3>
- <a href="load.php?page=1" target="ifr">Cha đẻ World Wide Web nhận Huy chương từ Nữ hoàng Anh</a><br>
- <a href="load.php?page=2" target="ifr">Sự thật chiến dịch giảm giá "kinh hoàng" của Intel</a><br>
- <a href="load.php?page=3" target="ifr">VNPT, EVN, Viettel "chung tay" ứng cứu kênh cáp quang quốc tế</a><br>
- <a href="load.php?page=4" target="ifr">Google xâm nhập Trung Quốc theo "đường vòng"</a><br>
</td>
Nửa trái liệt kê các liên kết, thuộc tính target thiết lập là ifr cho trình duyệt biết đích của liên kết. Phần bên phải có 1 thẻ DIV được định danh là news để tham chiếu bằng JavaScript, thẻ div này sẽ chứa nội dung các bài viết :
<td valign="top" width="400" style="background-color:#f4ffff;color:blue;">
<div id="news"></div>
</td>
</tr>
</table>
Cuối cùng chúng ta thêm 1 Iframe ẩn:
<iframe
id="ifr" name="ifr"
style="width:0px;height:0px;border:0px;"
src="load.php?page=1">
</iframe>
Trang load.php được code đơn giản như sau :
<html>
<head>
<script type="text/javascript">
function setTxt(){
var txt=document.cache.news.value;
parent.gTxt('news',txt);
}
</script>
</head>
<body onload="setTxt();">
<form name="cache">
<textArea name="news" style="width:0px;height:0px;">
<?
$page=addslashes($_GET['page']);
$str="";
$sql="Select * FROM tblNews WHERE NewsID='".$page."'";
// kết nối cơ sở dữ liệu MySQL, username=root, password rỗng:
$conn = mysql_connect("localhost","root","");
if(!$conn){
die('Could not connect database in this time ! ');
exit();
}
// Mở cơ sở dữ liệu có tên News để làm việc
mysql_select_db("News", $conn);
$result=mysql_query($sql);
if(mysql_num_rows($result)>0){
$row=mysql_fetch_array($result);
$str=$row['Story'];
}
mysql_free_result($result);
mysql_close($conn);
?>
<?=$str?>
</textArea>
</form>
</body>
</html>
Như vậy, bạn sẽ cần tạo 1 bảng tblNews đơn giản gồm 2 cột:
CREATE TABLE `tblNews` (
`NewsID` INT( 5 ) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
`Story` TEXT CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL ,
) ;
Chúng ta truy vấn cơ sở dữ liệu, tìm phần tin theo giá trị page trên chuỗi GET. Và nếu có mẩu tin tương ứng, chúng ta lấy giá trị Story gán vào biến $str. Nêu không tìm thấy mẩu tin nào, $str sẽ rỗng như khi nó được khởi tạo. sau cùng nó được gán vào trong textArea có tên news trong form cache.
Hàm setTxt được gọi trong biến cố onload, lấy giá trị trong textArea, và truyền như tham số vào hàm gTxt trên parent để gTxt gán chuỗi txt cho phần tử news.
Tất cả chỉ có vậy.
II. Chèn thêm Script
Một người sử dụng ít quan tâm đến kỹ thuật, chỉ thấy trang web như 1 sản phẩm ở giai đoạn cuối cùng, với hình ảnh, âm thanh, chữ nghĩa đầy màu sắc sinh động. Còn những người tạo web bằng các công cụ trực quan có thể biết đến trang web ở dạng thô, với các thẻ HTML, các đoạn script. Nhưng bạn, tìm hiểu sâu hơn, bạn sẽ thấy trang web còn thể hiện được ở dạng cây.
Đây là một hồ sơ HTML đơn giản và tuân theo đúng chuẩn DOM:
<html>
<head>
<title>SN Labs - Append Script </title>
</head>
<body>
<span id="msg">Hello</span>
<img src="myimage.gif"/>
</body>
</html>
Hồ sơ này mang cấu trúc XML, với nút gốc là html. Các tag không có tag đóng thì có ký tự "/" ở cuối tag mở. Và như vậy, hồ sơ này có thể biểu diễn ở dạng cây tương tự như 1 hồ sơ XML:
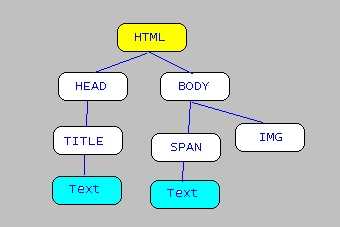
Trong cây trên, các nút như title, span, được xem là nút thành phần - element node, các nút chứa text như "SN Labs - Append Script", "Hello", gọi là text node.
Bất kỳ lúc nào, bạn cũng có thể dùng các phương thức của XML DOM để tác động vào hồ sơ, thêm và xóa các nút.
Để tạo 1 nút thành phần, chúng ta dùng phương thức createElement:
document.createElement(nodeName);
Để tạo 1 nút text, chúng ta dùng phương thức createTextNode:
document.createTextNode(text);
Các nút thành phần thường có nhiều thuộc tính, như IMG thì có thuộc tính src chỉ định nơi lưu trữ hình ảnh. SPAN có thuộc tính style định dạng kiểu dáng. Nếu bạn muốn nút tạo ra có các thuộc tính này, bạn chỉ đơn giản gán nó vào dưới dạng propertyName="value";
Sau khi tạo ra 1 nút, chúng ta có thể chèn thêm vào cây hồ sơ hiện thời bằng phương thức appenChild.
Script dưới đây sẽ tạo ra 1 thẻ DIV có chiều ngang 200px và chiều cao 40px:
oDiv=document.createElement("div");
oDiv.style.width="200px";
oDiv.style.height="40px";
nhuộm vàng nó:
oDiv.style.backgroundColor="#ffff55";
thêm 1 câu chào:
txt=document.createTextNode("Chào quý vị !");
nhét vào trong thẻ div vừa rồi:
oDiv.appendChild(txt);
và đặt vào hồ sơ HTML:
document.body.appendChild(oDiv);
Đó là nền tảng cơ chế làm việc của phương pháp chèn dữ liệu dạng script vào trang web mà chúng ta dựa trên đó để cập nhật động nội dung 1 webpage.
JavaScript hiện diện trong trang web dưới dạng thẻ script. Nếu xem xét theo mô hình DOM thì script cũng giống như mọi nút thành phần mà bạn có thể chèn thêm vào hồ sơ HTML bất cứ lúc nào cần đến. Để tiện sử dụng, chúng ta xây dựng 1 hàm nhỏ:
function apps(url){
var oScript = document.createElement("script");
oScript.src = url;
oScript.type = "text/javascript";
document.body.appendChild(oScript);
}
Rất dễ hiểu, apps nhận tham số url là đường dẫn sẽ được phần tử script sắp nhúng vào sử dụng làm thuộc tính src.
Bây giờ chúng ta làm 1 ví dụ.
Các website cho phép đăng ký tài khoản thường có 1 chế độ gọi là Check availability để người đăng ký kiểm tra nhanh cái tên mà họ muốn sử dụng vào dịch vụ này đã được cấp phát cho một người nào khác trước đó hay chưa. Sau khi bạn nhập tên mình chọn vào 1 textBox, bạn có thể click trên 1 button, và trang đăng ký sẽ âm thầm gửi truy vấn đến server, truy cập cơ sở dữ liệu, tìm kiếm cái tên mà bạn nhập vào xem đã dùng đến chưa. Nếu chưa có ai dùng tên này, nó thông báo ".. is available", ngược lại, nó sẽ báo "...is not available" để bạn chọn 1 cái tên khác.
Nhiều site tiến bộ hơn, sẽ ghi nhận sự kiện blur trên textBox đó, và tự động tiến hành kiểm tra trong khi bạn tiếp tục hoàn tất biểu mẫu. Đó chính là ý nghĩa đích thực của "asynchronous" trong cụm từ AJAX.
Để làm điều tương tự, chúng ta tạo 1 form chứa 1 textBox nhập username và 1 nút gọi lệnh kiểm tra :
Desired Login Name :<br>
<form name="reg">
<input name="username" value="" type="text"><br>
<input value="Check availability" onclick="check();" type="button"><br>
<div id="msg"></div>
</form>
Thẻ div "msg" sẽ trình bày thông báo kết quả kiểm tra.
Hàm check() của chúng ta như sau:
function check(){
var u=document.reg.username.value;
if(u!=""){
apps('check.php?username='+u);
}
}
check() trước tiên kiểm tra textBox có rỗng hay không, nếu chứa dữ liệu, nó gọi hàm apps để chèn vào 1 file JavaScript, hay chính xác hơn là 1 file php với dữ liệu trả xuống dưới dạng content-type=text/javascript, vì 1 file JavaScript thì không nhận được các tham số GET, POST.
Bây giờ là trang check.php:
<?php
header("Cache-Control: no-cache, must-revalidate");
header("Content-type: text/javascript");
$user=addslashes($_GET["username"]);
if($user!=""){
//giả định đầu tiên là chưa ai dùng cái username này
$exist=false;
$sql="Select * FROM tblUser WHERE Username='".$user."'";
// Mở kết nối với database
$conn = mysql_connect("localhost","root","");
if(!$conn){
die('Could not connect database in this time ! ');
exit();
}
// chọn cơ sở dữ liệu System :
mysql_select_db("System", $conn);
// Thực thi truy vấn :
$result = mysql_query($sql);
// Nếu có mẩu tin , nghĩa là tên đã được dùng :
if(mysql_num_rows($result)>0){
$exist=true;
}
mysql_free_result($result);
mysql_close($conn);
if(!$exist){
?>
gTxt('msg','<?=$user?> is available');
<?
}
else{
?>
gTxt('msg','<?=$user?> is not available');
<?
}
}
?>
Ở đây, bạn có 1 cơ sở dữ liệu tên là System, với 1 bảng tblUser để quản lý người dùng. Trong bảng này phải có cột Username lưu trữ các tên sử dụng.
Bạn lưu ý khi lấy $_GET["username"]:
$user=addslashes($_GET["username"]);
thì lúc này giá trị nhận được không phải từ trong trang đăng ký, mà từ 1 URL string của file check.php.
Dòng code thứ 3:
header("Content-type: text/javascript");
bắt buộc trình duyệt xem xét tài liệu gửi xuống như 1 một file JavaScript.
Do đó, bạn hãy quan tâm đến đoạn:
if(!$exist){
?>
gTxt('msg','<?=$user?> is available');
<?
}
else{
?>
gTxt('msg','<?=$user?> is not available');
<?
}
Về logic thì không có gì khó hiểu. Nếu trong database chưa có username $user, chúng ta gọi hàm gTxt để gán chuỗi '<?=$user?> is available' vào msg. Và tương tự cho trường hợp $user đã bị người khác đăng ký trước.
Nhưng điều thú vị là file script này được chèn trong 1 trang đã hoàn tất việc tải xuống. Vậy nếu bạn gọi check thêm một lần nữa thì sao ? Nghĩa là sẽ có thêm 1 file JavaScript nữa được chèn vào sau nó ? Đúng vậy. Nhưng trình duyệt luôn xử lý theo thứ tự ưu tiên tăng dần từ trên xuống dưới 1 cây hồ sơ HTML. Những thành phần tải sau, nằm dưới, sẽ được thực thi sau. Cũng như khi bạn nhiều lần gán giá trị cho 1 biến, nó sẽ chỉ nhận được giá trị cuối cùng:
var a=4;
a=15;
a=9;
b=a+1;
b sẽ mang giá trị 10.
Hạn chế của việc sử dụng phương pháp này để cập nhật động cho 1 trang web là chỉ có thể sử dụng giao thức GET. Mà GET thì có nghĩa là lộ liễu, dưới 1000 ký tự...
Tuy vậy, Append script vẫn có những giá trị thiết thực, chẳng hạn với các trang có chèn bộ gõ chữ Việt. Không phải lúc nào người dùng cũng cần đến nên chúng ta không nhất thiết phải tải song song với trang mà chỉ nên load xuống khi người dùng yêu cầu, cũng tiết kiệm được vài chục KB chứ ít gì đâu :)
*Note: các username bên cột Registered đã tồn tại trong database.
III. Sử dụng XML
Trong phần đầu tiên của topic này, chúng ta đã tìm hiểu cách sử dụng iframe để load trước dữ liệu và cập nhật nội dung cho 1 trang web mà không cần tải lại nó. Bây giờ chúng ta sẽ xem xét 1 phương pháp khác tinh tế hơn, đó là XML.
Chỉ tính riêng RSS và ASP .Net cũng đủ thấy những giá trị ứng dụng không nhỏ mà XML có thể đem lại cho chúng ta. Lần đầu tiên viết được 1 hàm xử lý XML, tôi cảm thấy thật sự hứng khởi. Cả thế giới vẫn không ngớt ca tụng XML như 1 công nghệ của tương lai. Và khi tôi biết được một chút gì đó về XML, điều đó có nghĩa giống như tôi đã nắm bắt được 1 phần tương lai của thế giới. Vĩ đại thay !
Nói đến XML là nói đến cấu trúc dữ liệu. Việc đầu tiên mà bất cứ nhà phát triển web nào cũng phải làm là hình dung dữ liệu sẽ được XML mô tả như thế nào. Mặt khác, chính cách tổ chức dữ liệu của bạn sẽ quyết định phương thức mà bạn phải làm để xử lý dữ liệu đó. Ở đây, thêm một lần nữa, chúng ta thấy rõ mối quan hệ chặt chẽ giữa cấu trúc dữ liệu và giải thuật.
Điều may mắn là XML khá trực quan. Chỉ cần bạn tưởng tượng một cách rõ ràng kết quả cuối cùng mà bạn muốn nhận được, thì bạn sẽ biết chắc bạn phải làm gì.
Trở lại với ví dụ ở phần đầu tiên, chúng ta có 1 bảng tblNews, bây giờ chúng ta sẽ thêm vào 1 trường là Title để thể hiện tiêu đề của 1 mục tin. Bảng sẽ có dạng sau:

Mong muốn của chúng ta là liệt kê 1 danh sách tiêu đề ở phần bên trái, sao cho khi nhấn lên mỗi tiêu đề thì nội dung tương ứng sẽ được load vào phần bên phải. Như hình ảnh này:

Cái mà chúng ta cần để trình bày là tiêu đề và nội dung của mỗi mục tin. Do vậy, cấu trúc XML của chúng ta có thể như dưới đây:

Bao giờ hồ sơ XML cũng yêu cầu 1 nút gốc. Bạn đặt tên gì cũng được. Còn ở đây tôi chọn nút gốc là SNNews. Dưới SNNews có 2 nút con title và story chứa tiêu đề và nội dung. Không cần giản đồ hay DTD gì cho mất thời gian, hãy đơn giản như bản chất của XML!
Giá trị của trường NewsID sẽ giúp chúng ta truy vấn mục tin trong cơ sở dữ liệu. 1 trang xml.php sẽ giúp tạo ra nội dung XML này. 2 câu lệnh header đầu tiên ngăn cản việc cache trang và quy định dữ liệu sẽ trả về theo khuôn dạng XML:
<?
header("Cache-Control: no-cache, must-revalidate");
header("Content-type: text/xml");
// Tạo 2 giá trị mặc định cho 2 node Title và Story.
$title="No data here";
$story="";
$id=trim($_GET['id']);
$sql="Select * FROM tblNews WHERE NewsID='".addslashes($id)."'";
// kết nối cơ sở dữ liệu MySQL từ localhostt, với username là root, password rỗng :
@$conn = mysql_connect("localhost","root","");
if(!$conn){
die('Could not connect database in this time ! ');
exit();
}
// Mở cơ sở dữ liệu có tên News để làm việc
mysql_select_db("News", $conn);
// thực hiện truy vấn SQL, trả kết quả vào biến $result :
$result=mysql_query($sql);
// Nếu có mẩu tin nào đó :
if(mysql_num_rows($result)>0){
// xem xét nội dung truy vấn ở dạng array :
$row=mysql_fetch_array($result);
// Gán lại nội dung của các phần tử mảng $row cho $title, và $story :
$title=$row['Title'];
$story=$row['Story'];
}
mysql_free_result($result);
mysql_close($conn);
// trình bày theo đúng định dạng XML
echo'<?xml version="1.0" encoding="UTF-8"?>';
?>
<SNNews>
<title><?=htmlspecialchars($title)?></title>
<story><?=htmlspecialchars($story)?></story>
</SNNews>
Code không phức tạp, tôi chỉ xin lưu ý 2 điểm:
-
Dòng mở đầu cho hồ sơ XML luôn có dạng:
<?xml version="1.0"?>Riêng dòng này trong PHP, bạn phải dùng chính PHP viết ra để tránh làm cho trình biên dịch hiểu nhầm đây là 1 đoạn PHP script, do cấu trúc thẻ có dạng
<?...?>. -
XML có 1 số ký tự riêng, mà nếu muốn dùng đến như 1 phần giá trị của node, bạn phải đưa về dạng thực thể ký tự. Do đó chúng ta dùng hàm htmlspecialchars.
Bạn cần kiểm tra lại sao cho ngay cả trong trường hợp không có mẩu tin nào truy xuất được, XML của bạn cũng không bị lỗi thì mới đảm bảo tính chính xác.
Bây giờ, chúng ta đi xuống phía khách. Kịch bản JavaScript như sau:
<script type="text/javascript">
function rel(ob){return document.getElementById(ob);}
function gTxt(ob,txt){rel(ob).innerHTML=txt;}
function loadNews(id){
var data=null, url="xml.php?id="+id;
if(document.implementation&&document.implementation.createDocument){
data=document.implementation.createDocument("","",null);
data.load(url);
data.onload=function (){parseXML(data);}
}
else if(window.ActiveXObject){
data=new ActiveXObject("Microsoft.XMLDOM");
data.async=true;
data.load(url);
data.onreadystatechange=function (){
if(data.readyState==4){
parseXML(data);
}
}
}
else{
alert("Sorry, your web browser is not yet supported.");
return;
}
}
function parseXML(data){
var root=data.getElementsByTagName("SNNews");
var title=root[0].getElementsByTagName("title")[0].firstChild.nodeValue;
var story=root[0].getElementsByTagName("story")[0].firstChild.nodeValue;
var s="<h4>"+title+"</h4>"+story;
gTxt('news',s);
}
</script>
Hàm loadNews nhận 1 tham số id, nó sẽ sử dụng tham số này để hoàn thiện url gọi đến file xml, bằng câu lệnh:
url="xml.php?id="+id;
Chúng ta cũng khởi tạo 1 biến data với giá trị null;
Theo đặc tả của W3C về DOM, đối tượng document có 1 thuộc tính implementation trả về 1 đối tượng DOMImplementation được trình duyệt sử dụng. Mozilla và Opera đều tuân thủ chuẩn này, nhưng IE trên Window thì không.
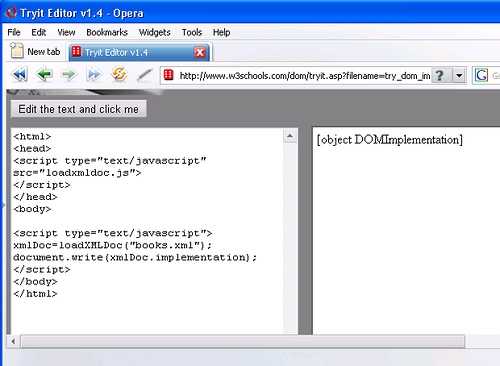
Phương thức createDocument của DOMImplementation, cho phép tạo ra 1 thể hiện của lớp này. Các tham số của phương thức createDocument được giới thiệu khá rõ trên W3Schools :
http://www.w3schools.com/dom/dom_parser.asp
Do đó, đầu tiên chúng ta kiểm tra trình duyệt có tuân thủ đúng chuẩn hay không, nếu có, chúng ta khởi tạo 1 instance của đối tượng xử lý DOMDocument và gán vào biến data. Phương thức load sẽ tải xuống hồ sơ XML theo đường dẫn chỉ định trong tham số của nó.
Khi load thành công, sự kiện onload trên data sẽ gọi hàm parseXML để duyệt cây hồ sơ XML. Nhưng hàm parseXML cần 1 tham số và chúng ta không thể viết :
data.onload=parseXML(data); // sai quy tắc
Vì vậy, tôi dùng 1 hàm động và gọi parseXML từ bên trong nó:
data.onload=function (){
parseXML(data);
}
Với IE, Microsoft đưa vào phiên bản 5.0 đối tượng ActiveX, có tên Microsoft.XMLDOM để làm nhiệm vụ xử lý dữ liệu XML. Phần kế tiếp của loadNews sẽ kiểm tra trình duyệt có ActiveX hay không, nếu có, chúng ta khởi tạo 1 thể hiện của Microsoft.XMLDOM và gán vào data.
else if(window.ActiveXObject){
data=new ActiveXObject("Microsoft.XMLDOM");
Thiết lập data.async=true chỉ định việc tải xuống hồ sơ XML đồng bộ. Nếu bạn đặt là false, có nghĩa là không cho phép điều này, và kịch bản sẽ dừng lại sau câu lệnh để chờ cho đến khi hồ sơ XML được tải xuống trọn vẹn rồi mới thực thi tiếp, giống như khi đang có một alert bật ra vậy.
data.load(url) cũng tương tự như trên. Phương thức này tải hồ sơ XML từ 1 url chỉ định.
Khi bạn thiết lập thuộc tính async là true, script sẽ tiếp tục thực thi song song với quá trình tải hồ sơ. Như vậy, chúng ta cần 1 cái gì đó để nắm bắt tiến trình load này và nhận biết khi nào trình duyệt tải xong. Script không thể phân tích 1 hồ sơ chưa đầy đủ. Vì vậy :
data.onreadystatechange=function (){
if(data.readyState==4){
parseXML(data);
}
}
Sự kiện onreadystatechange được kích hoạt khi thuộc tính readyState thay đổi giá trị. Một hàm động sẽ có nhiệm vụ theo dõi tiến trình cho đến khi readyState đạt tới giá trị 4, nghĩa là khi hồ sơ đã tải xuống hoàn chỉnh. Lúc đó, chúng ta mới gọi parseXML.
Hàm parseXML có nhiệm vụ phân tích dữ liệu trong DOMDocument Object, nó nhận vào 1 tham số là thể hiện của DOMImplementation hoặc Microsoft.XMLDOM. Với phương thức getElementsByTagName, chúng ta lấy phần tử gốc của cây hồ sơ XML và gán vào biến root. Ở đây, phần tử gốc theo cấu trúc của chúng ta định nghĩa là phần tử SNNews.
Hồ sơ chỉ có 1 phần tử SNNews duy nhất, chúng ta tham chiếu đến nó bằng chỉ mục là 0. Tiếp tục với getElementsByTagName, chúng ta lấy được các phần tử trực hệ của SNNews bằng cách gọi:
root[0].getElementsByTagName("title");
root[0].getElementsByTagName("story");
Tuy nhiên, nhằm truy xuất giá trị lưu trong các phần tử title và story để sử dụng, chúng ta code:
var title=root[0].getElementsByTagName("title")[0].firstChild.nodeValue;
var story=root[0].getElementsByTagName("story")[0].firstChild.nodeValue;
Bây giờ biến title sẽ chứa tiêu đề của mục tin, và story mang nội dung mục tin. Các câu lệnh cuối chỉ định script cho xuất hiện các giá trị này ra trình duyệt.
Tóm lại, mỗi khi bạn gọi loadNews(id), với id là giá trị trong trường ID của mục tin lưu trữ tại bảng tblNews, JavaScript sẽ gọi file xml.php với tham số GET cụ thể. Phía server, kịch bản PHP nhận được tham số GET, truy vấn cơ sở dữ liệu và trả về nội dung mục tin ở dạng XML để gửi trở lại trình duyệt khách. Java Script đón lấy hồ sơ XML này, dùng các thao tác của đối tượng DOMDocument và phân tích, xử lý để cuối cùng trình bày ra cho người sử dụng thấy nội dung mới.
Đó là toàn bộ quy trình hoạt động của ứng dụng mà chúng ta vừa xây dựng.
IV. Đối tượng XMLHttpRequest
AJAX là kết quả của một trò chơi ghép hình, trên sân chơi của những người tiên phong.
Có hai lý do khiến tôi liên tưởng AJAX với 1 trò xếp hình. Thứ nhất, AJAX là sự kết hợp của 2 mảnh ghép lớn: Java Script và XML. Thứ 2, về phía các ứng dụng Web - AJAX, cấu trúc của các trang luôn là 1 tổng thể của nhiều thành phần riêng biệt ghép lại, mà nội dung của mỗi thành phần có thể được cập nhật bất cứ lúc nào bạn muốn, trong khi không tác động đến những thành phần khác nằm cùng giao diện.
Vào năm 1993, Marc Andreessen và các cộng sự của anh ở Mosaic Communications Corporation đã sáng tạo ra Mosaic, trình duyệt đầu tiên trên thế giới. Cuối năm 1994, kết thúc thời gian thử nghiệm, Mosaic ra mắt cộng đồng với tên chính thức là Netscape Navigator. Netscape cũng là trình duyệt đầu tiên sử dụng Java Script và cookies.
Nhưng khi bước sang thế kỷ 21, trong lúc mà Netscape vẫn trung thành với công nghệ LiveConnect, Microsoft đã sớm nhận thấy khả năng tiềm ẩn của XML. Cùng với việc cho ra mắt công nghệ .Net Framework phía server, Microsoft cũng thêm vào phiên bản 5.0 của trình duyệt IE nhiều tính năng mới nhằm mở rộng khả năng xử lý dữ liệu XML cho phía client.
.Net Framework, còn được biết đến với tên NGWSF (Next Generation Web Services Framework), là một công nghệ dựa trên nền tảng XML, cho phép tạo ra các web services sử dụng giao thức SOAP để truyền tải dữ liệu, và triệu gọi lẫn nhau thông qua HTTP/HTTPS.
SOAP (Simple Object Access Protocol, hay Service Oriented Architecture Protocol) là một hình thức mới của POST trước đây, với phần dữ liệu được đóng gói theo khuôn dạng XML, cho phép mở rộng khả năng mô tả thông tin truyền tải, thay vì chỉ đơn thuần là các cặp name=value. SOAP đem dữ liệu được mô tả theo cú pháp của XML, ra vào các dịch vụ web qua cổng mặc định 80 của HTTP. Điều này giúp nó trở nên dễ được chấp nhận bởi firewall hơn so với các hình thức khác.
Ở thời điểm mới ra mắt, IE 5 là trình duyệt hỗ trợ XML đầy đủ nhất. Với IE, bạn có thể nhúng trực tiếp XML vào hồ sơ HTML bằng cặp thẻ XML. Nếu bạn cung cấp cho thẻ này 1 thuộc tính ID và gán giá trị định danh vào đó, bạn có một Data Island. File XML của bạn lúc này trở thành data source. Việc truy xuất dữ liệu từ data source để hiển thị ra trình duyệt có thể được thực hiện một cách đơn giản nhờ Data Island mà không cần đến ActiveX.
Trong ví dụ dưới đây, tôi có 1 file XML present.xml, nội dung như sau:
<?xml version="1.0"?>
<present>
<author>Larry</author>
<homePage>http://google.com</homePage>
<contactEmail>[email protected]</contactEmail>
</present>
Tôi nhúng nó vào 1 trang HTML bằng cặp thẻ XML có định danh data:
<xml id="data" src="present.xml"></xml>
Script sau sẽ truy xuất dữ liệu thông quan Data Island và hiển thị ra trình duyệt:
function parseXML() {
var oNode = data.documentElement;
var str = '';
if (oNode.hasChildNodes()) {
for (var i = 0; i < oNode.childNodes.length; i++) {
str += '<b>' + oNode.childNodes[i].nodeName + '</b>';
str += " : <font color=blue>" + oNode.childNodes[i].text + "</font><br>";
}
}
return str;
}
var p = parseXML();
document.write(p);
Hàm parseXML có nhiệm vụ đi sâu vào trong cây hồ sơ XML, tìm kiếm các node thứ cấp để cuối cùng trả về 1 chuỗi bao gồm tên và giá trị text của tất cả các node bên dưới node gốc.
Kết quả trên IE 7 sẽ có dạng:
author: Larry
homePage: http://google.com
contactEmail: [email protected]
Việc xử lý XML trên IE chỉ yêu cầu rất ít nỗ lực như vậy. Nhưng trong cuộc chạy đua về công nghệ web này, không có kẻ nào dừng lại nhường bước cho đối thủ. Netscape về với AOL, mã nguồn của trình duyệt Netscape Navigator trở thành open source. Mozilla Foundation phát triển code này để cho ra đời FireFox Mozilla, một trình duyệt mà nói theo cách của Thomas Friedman trong cuốn "Thế giới phẳng", đang "cưỡi nhẹ nhàng trên đỉnh Window".
Mozilla đưa FireFox rời khỏi LiveConnect để tập trung vào phát triển Java Script engine. Đây thực sự là một lựa chọn sáng suốt. Thừa hưởng nền Netscape, FireFox tự cho nó là chủ nhân của Java Script. Một loạt đối tượng mới được bổ sung vào nhân Java Script của FireFox, mà mục đích đầu tiên là tăng khả năng xử lý XML, sao cho bất cứ điều gì IE làm được thì FireFox cũng làm được, và những gì IE không làm được, FireFox chưa chắc đã không làm được.
Câu này nghe vui vui. Đây chúng ta chỉ nói về khả năng của JavaScript trong trình duyệt. Bạn hãy thử chạy script sau:
<script>
function Pow(x) x * x;
var a=Pow(5);
document.write(a);
</script>
Cho đến thời điểm này chỉ có duy nhất 1 trình duyệt là Gran Paradiso, tức FireFox 3.0, hiểu được script trên và hiển thị kết quả 25.
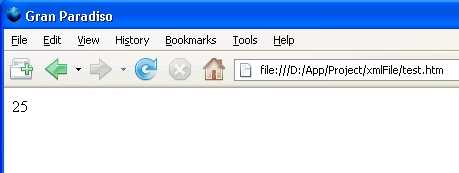
Vì lẽ đơn giản, hàm Pow, tính bình phương của 1 số, trong script trên được viết theo syntax của Java Script 1.8. Để các browser cũ hiểu được, phải viết đầy đủ như dưới đây:
function Pow(x) {
return x * x;
}
Bạn sẽ không sai nếu gọi IE 7.1, last version của MSIE là 1 trình duyệt cũ!
Trở lại với các thành phần hỗ trợ thao tác XML trong FireFox, có 3 đối tượng quan trọng là : XMLSerializer, DOMParser và XMLHttpRequest.
XMLHttpRequest làm việc theo cách tương tự 1 ActiveX có tên là XMLHTTP trong IE. Interface của nó như dưới đây:
interface XMLHttpRequest {
// event handler
attribute EventListener onreadystatechange;
// state
const unsigned short UNSENT = 0;
const unsigned short OPEN = 1;
const unsigned short SENT = 2;
const unsigned short LOADING = 3;
const unsigned short DONE = 4;
readonly attribute unsigned short readyState;
// request
void open(in DOMString method, in DOMString url);
void open(in DOMString method, in DOMString url, in boolean async);
void open(in DOMString method, in DOMString url, in boolean async, in DOMString user);
void open(in DOMString method, in DOMString url, in boolean async, in DOMString user, in DOMString password);
void setRequestHeader(in DOMString header, in DOMString value);
void send();
void send(in DOMString data);
void send(in Document data);
void abort();
// response
DOMString getAllResponseHeaders();
DOMString getResponseHeader(in DOMString header);
readonly attribute DOMString responseText;
readonly attribute Document responseXML;
readonly attribute unsigned short status;
readonly attribute DOMString statusText;
};
Nhìn vào interface, bạn có thể nhận biết toàn bộ các thuộc tính và phương thức cơ bản của XMLHttpRequest. Vì đây là đối tượng tạo sẵn trong Java Script engine, bạn sử dụng các thuộc tính và phương thức của XMLHttpRequest thông qua những thể hiện, như cách chúng ta vẫn làm với các đối tượng Array, Date...
Để FireFox hoặc Netscape làm điều mà IE đã làm với Data Island trong ví dụ đầu tiên, bạn có thể sử dụng đối tượng XMLHttpRequest như trong script sau:
function parseXML() {
var req = new XMLHttpRequest();
req.open("GET", "present.xml", false);
req.send(null);
var oNode = req.responseXML.getElementsByTagName('present')[0];
var str = '';
if (oNode.hasChildNodes()) {
for (var i = 0; i < oNode.childNodes.length; i++) {
if (oNode.childNodes[i].nodeValue == null) {
str += '<b>' + oNode.childNodes[i].nodeName + '</b>';
}
var k = oNode.childNodes[i];
if (k.hasChildNodes()) {
for (var j = 0; j < k.childNodes.length; j++) {
str += " : <font color=blue>" + k.childNodes[j].nodeValue + "</font><br>";
}
}
}
}
return str;
}
var p = parseXML();
document.write(p);
Hãy chạy thử trên các trình duyệt Netscape hoặc Firefox để xem kết quả thu được.
Iframe caching, mà chúng ta nói đến ở phần đầu tiên của topic này, không phải là AJAX. Đó chỉ là một sáng tạo của các nhà phát triển web trong thời kỳ tiền AJAX, nhằm đáp ứng một đòi hỏi chính đáng của người sử dụng. Đòi hỏi ấy là:
Hãy cho tôi xem nội dung khác, nhưng đừng bắt tôi phải tải lại cả trang!
XMLHttpRequest đã cung cấp một cách thức xử lý linh hoạt và dễ kiểm soát hơn cho cùng một công việc.
Trong số các phương thức của XMLHttpRequest, open() là đáng lưu ý nhất. Nó quyết định cách thức mà bạn sẽ phải viết script trong hàm xử lý. Trên interface, bạn có thể thấy phương thức này có 2 tham số bắt buộc là Method và chuỗi URI. Tham số thứ 3, Async, nhận vào 1 giá trị boolean.
Mặc định, async có giá trị true nếu bạn không cung cấp. Nếu async là false, script sẽ chờ cho tiến trình load kết thúc rồi mới thực thi phần kịch bản tiếp theo. Nếu async là true, script sẽ nhảy qua câu lệnh kế tiếp mà không chờ tiến trình load kết thúc, và bạn sẽ cần 1 hàm theo dõi tiến trình load để quyết định khi nào nên bắt đầu xử lý kết quả trả về.
URI là file đích sẽ tiếp nhận request. FireFox chỉ chấp nhận 1 đường dẫn tương đối. Nếu bạn cố gắng gửi yêu cầu đến 1 URL đầy đủ, ngay cả khi cùng 1 domain, bạn sẽ nhận 1 lỗi.
Method có thể giữ 1 trong các giá trị GET, POST, HEAD, PUT, DELETE hoặc OPTIONS . Tên của method được quy định viết kiểu chữ in, nằm trong ngoặc kép. GET, POST ở đây có vai trò như khi làm thuộc tính method của các form. Script trên đã tải xuống file present.xml bằng phương thức GET.
Nếu sử dụng giao thức POST, vì POST nén dữ liệu thành những packets khi giao dịch, nên ít nhất chúng ta phải có 1 dòng setRequestHeader để thiết lập Content-Type cho gói tin. Ví dụ dưới đây hàm doLogin nhận vào 2 tham số username, password và POST chúng lên 1 file login.php :
function doLogin(username, password) {
var req = request();
var $packet = "user=" + username + "& pwd=" + password;
if (typeof(req) != undefined) {
req.onreadystatechange = function() {
if (req.readyState == 4 && req.status == 200) {
// do something when data is received...
}
}
req.open("POST", 'login.php', true);
req.setRequestHeader("Content-Type", "application/x-www-form-urlencoded;");
req.send($packet);
}
}
Ở đây, hàm request có nhiệm vụ định nghĩa 1 thể hiện cho XMLHttpRequest trong Netscape hoặc XMLHTTP trong IE:
function request() {
var req = null;
if (XMLHttpRequest) {
req = new XMLHttpRequest();
} else if (window.ActiveX) {
req = new ActiveXObject("Msxml2.XMLHTTP");
if (!req) {
req = new ActiveXObject("Microsoft.XMLHTTP");
}
}
return req;
}
Trong file login.php sẽ có đoạn:
...
$Username=$_POST['user'];
$Password=$_POST['pwd '];
...
Các giá trị HEAD, PUT, DELETE ít thấy sử dụng cho Method, chúng ta sẽ dành thời gian để nói về SOAP. Như trên đã giới thiệu, SOAP là 1 giao thức mới, dựa trên POST. Bạn có thể dùng AJAX để gửi và nhận dữ liệu thông qua giao thức SOAP, nhưng cần thêm một số thiết lập khác trong code Java Script của bạn. Phần sau chúng ta sẽ tạo ra một Web Service đơn giản trên nền Apache/PHP để có thể làm một ví dụ về AJAX - SOAP.
Các khái niệm schema, namespace, XSD, DTD...
Vì SOAP là sự kết hợp giữ HTTP và XML, nên khi làm việc với SOAP, bạn cần nắm được những khái niệm cơ bản về XML, như namespace, XSD, DTD. Tôi thấy rằng chúng ta nên ôn lại các vấn đề này.
Mọi tài liệu XML, khi đưa vào sử dụng, đều cần phải thỏa mãn 2 điều kiện: định dạng đúng và hợp lệ.
Định dạng đúng là tuân thủ chính xác cú pháp của ngôn ngữ XML. Hợp lệ là tên của các phần tử trong hồ sơ phải phù hợp với các quy định nêu ra trong DTD hoặc XSD của nó.
DTD - Document Type Definion - là 1 file dạng text, chỉ định các phần tử nào được phép trong tài liệu XML. Một DTD giản lược cho các RSS có thể trông như thế này:
<!DOCTYPE RSS [
<!ELEMENT RSS(CHANNEL)>
<!ELEMENT CHANNEL(item+)>
<!ELEMENT item(title, description,link, pubDate)>
<!ELEMENT title(#PCDATA)>
<!ELEMENT description (#PCDATA)>
<!ELEMENT link(#PCDATA)>
<!ELEMENT pubDate(#PCDATA)>
<!ATTLIST CHANNEL CHAN CDATA #REQUIRED>
...
]>
Để biết thêm về DTD, hãy tham khảo tại đây.
XSD - XML Schema Definition - là một file dạng XML có chức năng tương tự DTD, nhưng cho phép quy định rõ hơn về kiểu dữ liệu của các phần tử trong hồ sơ. XSD có thể gọi tắt là schema. Một schema trông như sau:
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:tns="http://schemas.xmlsoap.org/soap/envelope/"
targetNamespace="http://localhost/shema.xml">
<xs:element name="MathPowResponse">
<xs:complexType>
<xs:sequence>
<xs:element name="num" type="xs:integer"/>
<xs:element name="result" type="xs:integer"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
Để có thêm thông tin về schema, hãy tham khảo :
http://en.wikipedia.org/wiki/Schema
http://www.w3schools.com/dtd/dtd_elements.asp
Các DTD và XSD được đưa vào hồ sơ XML thông qua thuộc tính xmlns. Điều này tạo ra các namespace - không gian tên. Nhờ các namespace, vấn đề trùng tên của các phần tử trong một tài liệu XML kết hợp từ nhiều nguồn, được giải quyết một cách dễ dàng.
Chẳng hạn dịch vụ Google News cung cấp các bản tin dạng RSS, với phần tử description mô tả tóm tắt về một tin tức. Trong khi Amazon lại cung cấp thông tin về 10 cuốn sách xuất bản gần nhất bằng một file dạng XML mà trong đó chứa các phần tử description giới thiệu về nội dung cuốn sách. Nếu bạn tổng hợp 2 tài liệu trên thành 1 hồ sơ XML của bạn, việc đưa các namespace vào để phân biệt 2 dạng sử dụng của description trong hồ sơ là cần thiết. và bạn làm như sau:
<gn:description xmlsn:gn="http://news.google.com/Schema">
New York utility workers searched through the night for...
</gn:description>
<am:description xmlsn:gn="http://amazon.com/Schema">
Here in our Harry Potter store we have something for everyone...
</am:description>
gn và am ở đây là tên rút gọn (short name) của các namespace. Chúng nằm trước tên của phần tử và ngăn cách với tên phần tử bằng dấu 2 chấm ;. Thuộc tính xmlsn sau đó cho biết tên phần tử được sử dụng theo cách định nghĩa trong các giản đồ ở địa chỉ http://news.google.com/Schema và http://amazon.com/Schema. (2 URL này chỉ mang tính minh họa).
Bạn cũng có thể đặt các quy ước cho short name ở phần đầu của hồ sơ XML, hay trong parent node của phần tử. Tất nhiên, phải quy ước trước khi sử dụng.
Đến đây, bạn có thể hiểu đoạn XML sau mang ý nghĩa gì chứ?
<SOAP-ENV:Envelope
xmlns:SOAP-ENC="http://schemas.xmlsoap.org/soap/encoding/"
SOAP-ENV:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:xsi="http://www.w3.org/1999/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/1999/XMLSchema">
<SOAP-ENV:Body>
<sn:MathPowResponse xmlns:sn="uri:http://localhost/shema.xml">
<sn:result>25</sn:result>
</sn:MathPowResponse>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>
Một cách khái quát, đoạn XML này mô tả 1 phần tử có tên là Envelope sử dụng short name là SOAP-ENV:
<SOAP-ENV:Envelope
Phần tử Envelope này có namespace ở http://schemas.xmlsoap.org/soap/envelope/ :
xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"
Tiếp đó là 1 phần tử Body. Phần tử này cũng sử dụng short name là SOAP-ENV, nhưng đã định nghĩa trên Parent node của nó là Envelope.
Tiếp đến là 1 phần tử MathPowResponse, tại đây có 1 short name khác tên là sn, chưa định nghĩa. Dó đó, nó cần được định nghĩa:
<sn:MathPowResponse xmlns:sn="uri:http://localhost/shema.xml">
Và cuối cùng là 1 phần tử result, cũng sử dụng short name sn, nhưng không cần định nghĩa lại nữa.
Trong thẻ Envelope còn 2 định nghĩa cho các shortname xsi và xsd. Bạn cũng thấy 1 khái niệm khác là encodingStyle. Mọi thông điệp SOAP đều có thuộc tính này. encodingStyle cho biết kiểu dữ liệu, cũng như quy tắc về tính tuần tự trong thông điệp SOAP.
Nếu làm việc với SOAP, bạn sẽ gặp nhiều đoạn XML như vậy hoặc có thể khác đôi chút, nhưng cũng không khó hiểu lắm đâu.
Web Service
Trong mô hình hoạt động của mỗi dịch vụ web, thông thường sẽ có 3 thành phần tham gia.
Đầu tiên là các nhà cung cấp dịch vụ, tạm gọi là Provider. Nếu bạn thuộc lớp này, công việc của bạn là xây dựng và cài đặt đối tượng dịch vụ lên 1 web server và cung cấp bản mô tả dịch vụ để hướng dẫn mọi người cách khai thác. Ngôn ngữ sử dụng cho các bản mô tả dịch vụ là SDL - Service Description Language, với cấu trúc cú pháp của XML.
Thành phần thứ 2: các nhà khai thác dịch vụ, tạm gọi là Consumer. Nếu bạn thuộc nhóm này, công việc của bạn là xem xét bản mô tả dịch vụ của nhà cung cấp, dựa vào đó để xây dựng lớp trung gian truy xuất đối tượng dịch vụ, và cuối cùng, thiết kế giao diện cho ứng dụng.
Thành phần thứ 3 trong chuỗi là những người dùng cuối, End - user. Họ truy cập trang web của các nhà khai thác dịch vụ, và sử dụng, một cách gián tiếp, Web Service của Provider.
Như vậy, Provider là người nhào bột. Consumer mang bột đó làm thành bánh và trưng bày ở các cửa hiệu. End-user đến cửa hiệu, thưởng thức bánh và thường là không cần biết ai đã nhào bột !
PHP và SOAP
PHP, ngôn ngữ lập trình hướng đối tượng có mã nguồn mở, sử dụng trên các máy chủ web, được sáng tạo bởi Rasmus Lerdorf vào năm 1994, trong hơn 10 năm qua đã trở thành niềm say mê của không ít người phát triển ứng dụng web. Những người yêu thích PHP và có tài năng, chủ yếu quy tụ ở http://www.php.net và http://www.zend.com/, không ngừng bổ sung cho PHP các tính năng mới nhằm đáp ứng với những đổi thay của công nghệ.
Muốn thêm tính năng vào PHP, người ta sẽ dùng một ngôn ngữ lập trình cao cấp nào đó để tạo ra các lớp đối tượng và phương thức nhằm thực thi một nhóm tác vụ cụ thể, rồi biên dịch thành những file dạng DLL - Dynamic Link Library - và đặt vào thư viện mở rộng của PHP. Người viết mã PHP sau đó chỉ cần tạo ra thể hiện của những đối tượng xây dựng sẵn trong thư viện và gọi các phương thức của chúng.
Có một dạng thư viện khác không được biên dịch trước, với những lớp đối tượng tạo sẵn nằm trong các file PHP. Khi sử dụng, người viết mã phải chèn file thư viện vào trang PHP của họ bằng các chỉ thị include, require... Việc sử dụng các thư viện không biên dịch sẽ đòi hỏi nhiều thời gian xử lý hơn, nhưng đôi khi, đó lại là cách lựa chọn duy nhất.
Để làm việc với SOAP trong PHP, bạn cần đảm bảo web server đã có thư viện php_soap.dll. Nếu chưa có, bạn tải về và đặt file này vào folder các thư viện mở rộng mà việc ấn định nằm trong file php.ini ở dòng:
extension_dir = path
Đồng thời, cũng cần kiểm tra lại file php.ini để chắc chắn có các dòng sau :
extension=php_soap.dll
always_populate_raw_post_data = On
Nếu chưa có, hãy thêm vào. Nếu đang ở dạng chú thích, hãy gỡ bỏ comment. Nếu giá trị thiết lập không đúng như trên, hãy sửa lại.
Thư viện php_soap.dll cung cấp 2 đối tượng chính : SoapServer và SoapClient. Mọi thông tin về 2 đối tượng này, bạn có thể tham khảo tại đây.
SoapServer chủ yếu phục vụ cho việc xây dựng web service, cài đặt đối tượng dịch vụ web, tự động tạo ra bản mô tả dịch vụ. SoapClient chủ yếu dùng trong quá trình khai thác dịch vụ web, triệu gọi đối tượng web service và nhận phản hồi từ nhà cung cấp.
Trong trường hợp bạn không có quyền can thiệp vào file cấu hình PHP, và không thể cài đặt thêm php_soap.dll, bạn có thể sử dụng các thư viện hỗ trợ SOAP không cần biên dịch, như NuSOAP, PearSOAP... NuSOAP tỏ ra khá hiệu quả vì tên các đối tượng trong thư viện này gần giống với trong thư viện php_soap.dll. 2 đối tượng quan trọng nhất ở NuSOAP là soap_server và soap_client có các chức năng gần tương tự SoapServer và SoapClient trong thư viện php_soap.dll.
Nếu bạn cần các thư viện, có thể download ngay tại đây
Trong ví dụ minh họa cho AJAX - SOAP dưới đây, tôi sẽ sử dụng thư viện NuSOAP.
Xây dựng Web Service
Giả sử chúng ta muốn cung cấp một dịch vụ có tên là Reverse String, với phương thức Reverse cho phép đảo ngược một chuỗi text bất kỳ. Chẳng hạn khi bạn đưa vào một chuỗi "I saw Elba", cái mà bạn nhận được sẽ là "ablE was I". Vậy thì trước tiên, chúng ta tải xuống file NuSOAP.zip, giải nén và đặt thư mục libs vừa có được vào đâu đó trong thư mục ứng dụng web để chèn vào trang khi cần. Ở đây tôi đặt vào thư mục gốc.
Tiếp theo chúng ta tạo ra 1 folder cùng cấp với libs, đặt tên là Provider, mở ra và tạo 1 file service.php, có nội dung như sau :
<?php
include('../libs/nusoap.php');
$server = new soap_server();
$server->configureWSDL('Reverse String', 'uri:http://snlibs.googlepages.com/schema.xml');
function Reverse($s){
$r='';
for($i=1;$i<=strlen($s);$i++){
$r.=substr($s,-$i,1);
}
return $r;
}
$server->register("Reverse", array('text' => 'xsd:string'),array('result' => 'xsd:string'));
$query = isset($HTTP_RAW_POST_DATA)? $HTTP_RAW_POST_DATA : '';
$server->service($query);
?>
Sau khi chèn thư viện NuSOAP vào trang, chúng ta khởi tạo 1 thể hiện của lớp soap_server trong biến $server. Phương thức configureWSDL nhận vào 2 tham số là tên của dịch vụ web, và đường dẫn đến giản đồ sử dụng cho dịch vụ.
Hàm Reverse tiếp nhận 1 chuỗi văn bản, và lật ngược nó, được cài đặt vào dịch vụ thông qua phương thức register của soap_server. Nó cần 3 tham số : tên của hàm, mảng các request và mảng các response. Ở đây, request là các yêu cầu mà dịch vụ muốn nhận được khi triệu gọi; response là các thông điệp trả về lớp trung gian. Phương thức register tương đương với addFunction của SoapServer trong php_soap.dll.
Câu lệnh:
$query = isset($HTTP_RAW_POST_DATA)? $HTTP_RAW_POST_DATA : '';
sẽ đem mọi dữ liệu nhận được qua HTTP - POST gán vào biến $query. Bạn chỉ nhận được dữ liệu post lên theo cách này khi trong file php.ini, always_populate_raw_post_data đã được thiếp lập giá trị On.
Và cuối cùng, phương thức service sẽ thực hiện việc gọi hàm Reverse để đảo ngược chuỗi $query. Phương thức service tương đương với handle của SoapServer trong php_soap.dll.
Nếu không có gì sai sót, khi bạn gọi http://localhost/Provider/service.php, sẽ thấy kết quả như sau:

Bản mô tả dịch vụ xuất hiện khi bạn cung cấp tham số query ?wsdl.
Còn một điểm cuối cùng cho Web Service là schema, chúng ta thêm vào cho đủ đội hình. Đây là nội dung của schema.xml:
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs=" http://www.w3.org/2001/XMLSchema"
xmlns:tns=" http://schemas.xmlsoap.org/soap/envelope/"
targetNamespace="http://snlibs.googlepages.com/schema.xml">
<xs:element name="ReverseRequest">
<xs:complexType>
<xs:sequence>
<xs:element name="text" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="ReverseResponse">
<xs:complexType>
<xs:sequence>
<xs:element name="result" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
SOAP gửi và nhận dữ liệu ở dạng XML, schema trên sẽ quy định các phần tử xuất hiện trong thông điệp HTTP - XML mà SOAP chuyển đi. Trong thông điệp triệu gọi, chúng ta có 1 phần tử ReverseRequest và 1 phần tử text. Trong thông điệp phản hồi, chúng ta có ReverseResponse và 1 phần tử result. 2 phần tử text và result đều có kiểu dữ liệu string.
Như vậy, chúng ta đã hoàn chỉnh phần thiết lập cho dịch vụ web. Bây giờ, hãy chuyển sang vai trò của một nhà khai thác dịch vụ.
Khai thác dịch vụ web
Xem xét bản mô tả khi gọi trang http://localhost/Provider/service.php/Reverse?wsdl, bạn có thể nhận thấy :
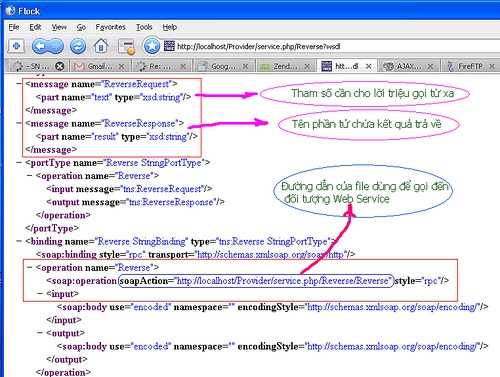
Có 2 phần tử message, 1 chỉ định tên của tham số dùng cho lời triệu gọi: text, và 1 cho biết tên của phần tử sẽ chứa kết quả trả về : result.
Phần tử operation cho biết tên của phương thức: Reverse, và URL dùng để gọi hành động SOAP.
Chừng đó kể như là đủ cho việc tạo ra ứng dụng trung gian. Cũng trong thư mục chứa Provider và libs, chúng ta tạo ra 1 folder có tên là Consumer, mở ra và tạo 1 file call.php có nội dung như sau:
<?php
header("Content-Type: text/xml; charset=utf-8");
include('../libs/nusoap.php');
$query = isset($HTTP_RAW_POST_DATA)? $HTTP_RAW_POST_DATA : 0;
$sp = new soap_parser($query, 'UTF-8', 'POST');
$text=$sp->buildVal(3);
$c = new soapclient('http://localhost/Provider/service.php/Reverse');
$c->call('Reverse', array('text'=>$text));
echo $c->responseData;
?>
Dòng lệnh đầu tiên quy định dữ liệu mang định dạng XML. SOAP và XML không thể tách rời nhau. Thư viện NuSOAP được chèn vào ở dòng lệnh thứ 2. Biến $query đón bắt các thông điệp post lên từ máy khách.
Vì chúng ta post request lên bằng AJAX- SOAP, và dữ liệu có định dạng XML nên tôi tạo ra một thể hiện của lớp soap_parser để lấy chuỗi văn bản trong phần tử text.
Đối tượng soap_parser khi khởi tạo cần có 3 thuộc tính: dữ liệu XML (là chuỗi text mà AJAX gửi lên và nằm trong biến $query), bảng mã sử dụng trong tài liệu XML, và phương thức gửi nhận dữ liệu.
soap_parser cung cấp phương thức buildVal, cho phép lấy dữ liệu từ 1 phần tử bất kỳ trong tài liệu XML thông qua chỉ mục của phần tử. Theo cấu trúc của thông điệp SOAP mà chúng ta gửi lên, văn bản do người dùng nhập vào sẽ nằm ở node thứ 3.
Tiếp đó, chúng ta khởi tạo 1 thể hiện của lớp soap_client. Cần 1 tham số là URL của dịch vụ web mà chúng ta có nhờ sự chỉ dẫn của bản mô tả dịch vụ.
Phương thức call sẽ yêu cầu dịch vụ thực hiện Reverse chuỗi text. Đây là bước triệu gọi web sevice. Nếu dùng thư viện php_soap.dll, bạn tạo ra thể hiện của lớp SoapClient và gọi Reverse như sau:
$c = new SoapClient("http://localhost/Provider/service.php/Reverse");
$c->__soapCall('Reverse', array('text'=>$text));
// hoặc : $c->__call('Reverse', array('text'=>$text));
Và cuối cùng, phương thức responseData của soap_client trả về kết quả phản hồi từ Provider. Nó tương đương với getLastResponse của SoapClient trong thư viện php_soap.dll.
call.php đóng vai trò trung gian, sẽ nhận tham số là chuỗi text do người dùng post lên, và chuyển cho Provider. Khi dịch vụ web của Provider nhận được chuỗi text, nó dùng phương thức Reverse đảo ngược chuỗi rồi trả kết quả trở lại.
Thư viện NuSOAP còn có nhiều đối tượng và phương thức xử lý khác. Để đưa vào hoạt động thực sự, bạn nên sử dụng các phương thức xử lý lỗi của lớp soap_fault. Ứng dụng này chỉ mang tính minh họa và chúng ta chỉ mới khai thác một cách rất hạn chế những gì có trong NuSOAP.
Gửi nhận data với AJAX và SOAP
Việc giao dịch giữa người dùng cuối và trang trung gian sẽ được thực hiện bởi AJAX-SOAP. Đây là hàm JavaScript trong file index.htm đảm nhiệm chức năng đó:
function soap_request(oText){
var s='<'+'?'+'xml version="1.0" encoding="UTF-8"'+'?'+'>';
s+='<SOAP-ENV:Envelope ';
s+= ' xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"';
s+= ' SOAP-ENV:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/">';
s+= '<SOAP-ENV:Body>';
s+= '<sn:ReverseRequest xmlns:sn="http://snlibs.googlepages.com/schema.xml">';
s+= '<sn:text>'+oText+'</sn:text>';
s+= '</sn:ReverseRequest>';
s+= '</SOAP-ENV:Body>';
s+= '</SOAP-ENV:Envelope>';
var xmlhttp=request();
xmlhttp.onreadystatechange=function(){
if (xmlhttp.readyState==4&&xmlhttp.status==200){
setResult(xmlhttp.responseText);
}
}
xmlhttp.open("POST", "call.php",true);
xmlhttp.setRequestHeader("SOAPAction", 'http://localhost/Provider/service.php/Reverse');
xmlhttp.setRequestHeader("Content-Type", "text/xml; charset=utf-8");
xmlhttp.setRequestHeader('Content-Length', s.length);
xmlhttp.send(s);
}
Hàm này nhận vào 1 tham số là chuỗi ký tự do người dùng nhập vào. Chuỗi s được biên tập theo dạng XML, với tham số oText lồng vào trong phần tử text để trở thành giá trị của phần tử này. Các dòng setRequestHeader thiết lập thông số trong header của gói tin SOAP gửi đi. Khi đã nhận được thông điệp phản hồi, hàm setResult được gọi với tham số là dữ liệu trả về dạng text/html.
Tôi chọn responseText thay vì responseXML để có thể vừa lấy ra giá trị text trong phần tử result, vừa có thể trình bày lại nguyên dạng thông điệp HTTP-SOAP trả về từ web service trong 1 textArea. Đây là hàm setResult.
function setResult(str){
var r='',xmlDoc=null;
if(window.DOMParser){
var parser = new DOMParser();
xmlDoc = parser.parseFromString(str, "text/xml");
}
else{
xmlDoc=new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async="false";
xmlDoc.loadXML(str);
}
r=xmlDoc.getElementsByTagName('result')[0].childNodes[0].nodeValue;
document.f.result.value=r;
document.f.responseMsg.value=str;
}
setResult kiểm tra xem trình duyệt có lớp DOMParser hay không, nếu có, thì tạo ra một thể hiện và gán vào xmlDoc. Đây là trường hợp của FireFox và Opera. Phương thức parseFromString của DOMParser cho phép chuyển một chuỗi về dạng XML để thao tác như với dữ liệu XML.
Chẳng hạn bạn có chuỗi s='<result>13479</result>', đây không phải là dữ liệu trong 1 hồ sơ XML nên bạn không thể xử lý result như phần tử XML. Và bạn cần parseFromString để làm điều đó.
Ngược lại với parseFromString là phương thức serializeToString của đối tượng XMLSerializer, nó cho phép bạn xem xét hồ sơ XML như với 1 chuỗi bình thường.
Trên IE không có DOMParser, vì vậy chúng ta khởi tạo XMLDOM và gọi phương thức loadXML để load chuỗi str vào đó. Hành động này cũng chuyển tham số str về dạng XML để có thể truy vấn node được.
Sau khi có thể xem xét str như 1 tập hợp XML node, chúng ta lấy trị trong node result và gán vào biến r. Cuối cùng chỉ còn việc hiển thị :
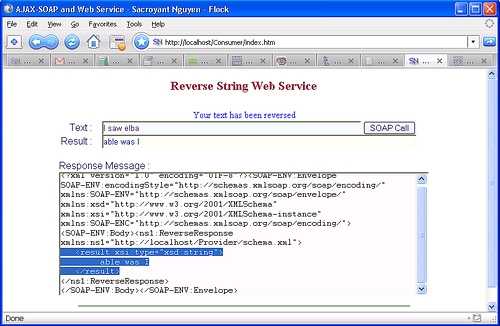
Kết luận
Bài viết này cung cấp một cái nhìn tổng quan về các kỹ thuật tải dữ liệu khác nhau được sử dụng trong phát triển web hiện nay. Việc hiểu rõ về iframe, script injection, XML, XMLHttpRequest và AJAX-SOAP sẽ giúp bạn xây dựng những trang web chạy nhanh và thân thiện không kém gì ứng dụng desktop. Mỗi kỹ thuật có những ưu thế và hạn chế riêng, lúc sử dụng nên linh hoạt, tùy trường hợp mà thiết kế. Cũng cần lưu ý thêm về tính bảo mật và an toàn dữ liệu khi chạy kịch bản tương tác giữa client và server.
Chúc các bạn thành công.